
CI's can be put around any kind of sample-based statistic, such as a percentage, a mean, or a correlation, to produce a range for estimating the true value in the larger population (i.e., what the percentage, mean, or correlation would be if you surveyed the full population).
Besides allowing one to see the likely range of possible values of a parameter in the population, CI's can also be used for significance-testing. A 95% CI is most commonly used, corresponding to p < .05 significance.
The following chart presents visual depictions of 95% confidence intervals, based upon correlations reported in this article on children's physical activity. (On some computers, the image below may stall before its bottom portion appears; if you click on the image to enlarge it, you should get the full picture, which features a continuum of correlations from -.30 to .30 at the bottom.)

An important thing to notice from the chart is that there's a direct translation from a confidence interval around a sample correlation to its statistical significance. If a CI does not include zero (i.e., is entirely in positive "territory" or entirely in negative "territory"), then the result is significantly different from zero, and we can reject the null hypothesis of zero correlation in the population. On the other hand, if the CI does include zero (i.e., straddles positive and negative territory), then the result cannot be significantly different from zero, and Ho is maintained. As Westfall and Henning (2013) put it:
...the confidence interval for [a parameter] provides the same information [as the p value from a significance test] as to whether the results are explainable by chance alone, but it gives you more than just that. It also gives the range of plausible values of the parameter, whether or not the results are explainable by chance alone (p. 435).
The dichotomous nature of null hypothesis significance testing (NHST) -- the idea that a result either is or is not significantly different from zero -- makes it less informative than the CI approach, where you get an estimated range within which the true population value is likely to fall. Therefore, many researchers have called for the abolition of NHST in favor of CI's (for an example, click here).
Of course, even if only CI's are presented, an interpretation in terms of statistical significance can still be made. Thus, it seems, we can have our cake and eat it too! Of that you can be confident.
This next posting shows how to calculate CI's and also includes a song...
Besides allowing one to see the likely range of possible values of a parameter in the population, CI's can also be used for significance-testing. A 95% CI is most commonly used, corresponding to p < .05 significance.
The following chart presents visual depictions of 95% confidence intervals, based upon correlations reported in this article on children's physical activity. (On some computers, the image below may stall before its bottom portion appears; if you click on the image to enlarge it, you should get the full picture, which features a continuum of correlations from -.30 to .30 at the bottom.)
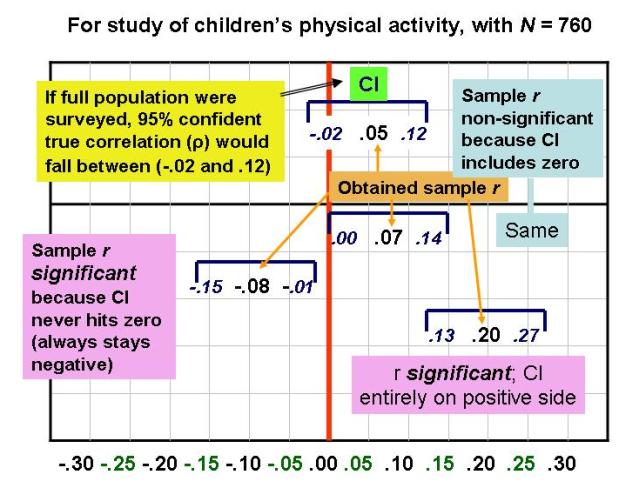
An important thing to notice from the chart is that there's a direct translation from a confidence interval around a sample correlation to its statistical significance. If a CI does not include zero (i.e., is entirely in positive "territory" or entirely in negative "territory"), then the result is significantly different from zero, and we can reject the null hypothesis of zero correlation in the population. On the other hand, if the CI does include zero (i.e., straddles positive and negative territory), then the result cannot be significantly different from zero, and Ho is maintained. As Westfall and Henning (2013) put it:
...the confidence interval for [a parameter] provides the same information [as the p value from a significance test] as to whether the results are explainable by chance alone, but it gives you more than just that. It also gives the range of plausible values of the parameter, whether or not the results are explainable by chance alone (p. 435).
The dichotomous nature of null hypothesis significance testing (NHST) -- the idea that a result either is or is not significantly different from zero -- makes it less informative than the CI approach, where you get an estimated range within which the true population value is likely to fall. Therefore, many researchers have called for the abolition of NHST in favor of CI's (for an example, click here).
Of course, even if only CI's are presented, an interpretation in terms of statistical significance can still be made. Thus, it seems, we can have our cake and eat it too! Of that you can be confident.
This next posting shows how to calculate CI's and also includes a song...
---
*How exactly to interpret a confidence interval in technical terms remains in dispute (see Hoekstra et al. [2014] vs. Miller & Ulrich [2015] for contrasting arguments). My lecture notes above are closer to Miller and Ulrich's perspective.